I felt like putting in writing a few thoughts I often find myself telling my students, and hence this post. You can download a (nicer) PDF version of it here.
Theory versus Practice: A Challenge
It was a rainy Saturday afternoon…
“Ready? Go!”
As she reached for her pencil and began scribbling, I opened an empty Excel spreadsheet and started typing in the data and thinking out loud.
“Eight integer variables, three constraints, plus lower and upper bounds. How is it going over there?”
“I’m doing OK. Let me think.”
A minute later, I click “Solve” and declare victory.
“There you go: $2.80. Can’t beat that!”
“Five buns? Do you expect people to eat a burger with five buns?”
“Hmm…you’re right. One more constraint… voilà $2.62. The best burger on the market! What did you get?”
“Mine costs $2.61.”
“I win! Ha, ha!”
“But look at your burger! Nobody would ever want to eat this crap. Mine is much more appetizing.”
As I reluctantly examined the two solutions, there was no denying the obvious.
That was me and my wife solving the Good Burger puzzle. The challenge is to create the most expensive burger out of a given set of ingredients such as beef patties, cheese, lettuce, tomato, etc., while keeping sodium, fat, and calorie counts in check. Her hand-calculated solution was suboptimal by one cent. It was technically worse than mine, but what does optimality really mean in practice?
Optimality or Bust?
Once upon a time, at the board meeting of a for-profit company…
“Today, I’m excited to report the results from the cost-cutting initiative that my team of analytics experts developed over the last six months. We managed to produce a solution to our problem that improves profits by 6%.”
“But is this solution optimal?”
Said no one ever after hearing “improves profits by 6%.”
Intangibles and Intuition
The two anecdotes above illustrate an important idea that I emphatically stress to my students every spring semester: models aren’t perfect, and that’s perfectly OK. There’s a reason why business analytics is known as “the science of better” rather than “the science of provably optimal.” More often than not, it is impossible to capture all nuances of a real-life problem into a mathematical model. Therefore, solutions produced by such a model are to be taken with a grain of salt and cautious optimism. Do these numbers still make sense after the omitted intangibles are brought back into the picture? If so, great. If not, can we slightly modify the solution? Do we need to revise the model? When building my burger, I ignored flavor considerations and overall gastronomic appeal, whereas my wife didn’t.
Another matter with which non-experts struggle is keeping their intuition from negatively affecting their modeling choices. Or, as I like to say in class, “don’t try to solve the problem; focus on representing the problem.” A mathematical model is a translation, say, from English to formulas, of the story that warrants investigation. Letting your understanding of the story bias you into thinking the solution should/shouldn’t look a certain way, and adding that assumption into your model, can be detrimental. As humans, we tend to think intuitively, which in turn limits the universe of possibilities we look at. Good solutions to complex problems can be, at least at first sight, counterintuitive. Make sure your model has the freedom to consider “weird” courses of action as well.
The Usefulness of Imperfection
Imperfect models create imperfect solutions that can still be useful. Having a solution in the ballpark of good answers is better than looking at a blank slate and not knowing where to begin. Solving a model many times with a range of input values improves your understanding of how certain numbers relate to others. As your understanding of the problem improves, that (initially) counterintuitive solution starts to make sense. Improved understanding leads to revising your initial assumptions and even realizing that what you thought mattered is secondary. What really matters is this other number to which you didn’t pay much attention to begin with. In extreme cases, this first model may lead you to conclude that you need to create a completely different model to solve a completely different problem, and that’s OK too! You are learning about your problem in the process of trying to solve your problem. Finally, it may very well be that your problem, as originally stated, has no solution. This would have been difficult to detect by hand because complex problems have several moving parts with intricate relationships of cause and effect. Having a model whose output says “infeasible” can be a valuable tool in a meeting. It is concrete proof that the original question and/or assumptions are inconsistent in some way. (Assuming there’s no mistake in the model, of course.) From there, it will be a much shorter path to convincing people to revise the question/assumptions than it would have been otherwise. Who would have thought? Modeling also makes your meetings more efficient!

 A couple of weeks ago, I wrote a blog post in which I tell a story that motivated me to start creating games for children and young adults to get them excited about Operations Research/Prescriptive Analytics/Optimization and STEM in general. You can download my first two games here: Lego Furniture and Pack That Bag!
A couple of weeks ago, I wrote a blog post in which I tell a story that motivated me to start creating games for children and young adults to get them excited about Operations Research/Prescriptive Analytics/Optimization and STEM in general. You can download my first two games here: Lego Furniture and Pack That Bag!


 As I sat through a 4-hour meeting the other day, I had an idea for a very useful and generic prescriptive analytics model to be used in conjunction with the results of a statistical learning study (e.g. a regression model). I can immediately see a large number of applications for this model, some of which I’ll illustrate in this post. I also believe this idea could be turned into an interesting case study (combining predictive and prescriptive analytics) for class discussion in a master’s level course (MBA or specialized MS), and I’d love to partner with someone to turn that into reality. Let me know if you’d like to pursue this! (Disclaimer: I don’t have much experience writing cases, but I want to get better at it.)
As I sat through a 4-hour meeting the other day, I had an idea for a very useful and generic prescriptive analytics model to be used in conjunction with the results of a statistical learning study (e.g. a regression model). I can immediately see a large number of applications for this model, some of which I’ll illustrate in this post. I also believe this idea could be turned into an interesting case study (combining predictive and prescriptive analytics) for class discussion in a master’s level course (MBA or specialized MS), and I’d love to partner with someone to turn that into reality. Let me know if you’d like to pursue this! (Disclaimer: I don’t have much experience writing cases, but I want to get better at it.) , that certain agents will perform a given action that benefits you. So you hire a group of business analytics consultants who create a statistical learning model M that predicts the value of
, that certain agents will perform a given action that benefits you. So you hire a group of business analytics consultants who create a statistical learning model M that predicts the value of  (a subjective choice), don’t concern you too much because they’re already on your side. Your focus is on those whose value of
(a subjective choice), don’t concern you too much because they’re already on your side. Your focus is on those whose value of 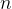 agents, for each agent
agents, for each agent  , let
, let  be how much the agent’s action probability (before the incentive) is below my target threshold, and let
be how much the agent’s action probability (before the incentive) is below my target threshold, and let 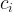 be how much agent
be how much agent 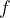 dollars of financial incentive. In my example above,
dollars of financial incentive. In my example above,  (50% minus 35%),
(50% minus 35%),  , and
, and  .
. is an integer number indicating how many
is an integer number indicating how many  is a binary (yes/no) variable indicating whether or not we manage to bring agent
is a binary (yes/no) variable indicating whether or not we manage to bring agent 
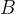 , we respect the budget with the following constraint (note that the sum of all
, we respect the budget with the following constraint (note that the sum of all 
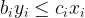


 be the number of times we go to the vending machine to load $1 on the card. Let
be the number of times we go to the vending machine to load $1 on the card. Let  be the number of times we load $2.25 on the card, and so on all the way to
be the number of times we load $2.25 on the card, and so on all the way to  (how many times we load $40). To minimize the number of visits to the vending machine, we write the objective function
(how many times we load $40). To minimize the number of visits to the vending machine, we write the objective function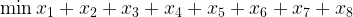

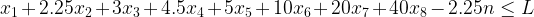
 is a limit on what we’d be willing to have left on the card after the
is a limit on what we’d be willing to have left on the card after the 
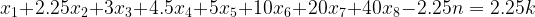
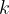 is a new, non-negative integer variable. The sheet called “leftover is multiple” in
is a new, non-negative integer variable. The sheet called “leftover is multiple” in  , and the value of
, and the value of  O.R. researchers and practitioners are constantly churning out papers that tackle a wide variety of important and hard-to-solve practical problems. On one hand, as a researcher, I understand how difficult these problems can be and how it’s often the case that fancy math and complex algorithms need to be used. On the other hand, as someone who teaches optimization to MBA students who aren’t easily excited by mathematics, I’m always looking for motivational examples that are both interesting and not too complex to be understood in 5 minutes. (That’s the little slot of time I reserve at the beginning of my lectures to go over an application before the lecture itself starts.)
O.R. researchers and practitioners are constantly churning out papers that tackle a wide variety of important and hard-to-solve practical problems. On one hand, as a researcher, I understand how difficult these problems can be and how it’s often the case that fancy math and complex algorithms need to be used. On the other hand, as someone who teaches optimization to MBA students who aren’t easily excited by mathematics, I’m always looking for motivational examples that are both interesting and not too complex to be understood in 5 minutes. (That’s the little slot of time I reserve at the beginning of my lectures to go over an application before the lecture itself starts.)

