
To celebrate the start of the 2013-2014 NBA season this past Tuesday, I decided to write a post on basketball. More specifically, on the important issue of how to give players some much needed rest in an “optimal” way. My inspiration came from an article by Michael Wallace published on ESPN.com on October 19. Here are some relevant excerpts:
After playing in the Miami Heat’s first five preseason games, LeBron James sat out Saturday night’s 121-96 victory over the San Antonio Spurs to rest…James said the decision to sit was part of the team’s “maintenance” process. Heat teammate Dwyane Wade played Saturday and scored 25 points in 26 minutes, but previously skipped three preseason games…”No, no injuries — just not suiting up,” James said. “It’s OK for LeBron to take one off.”
The key term here is maintenance process. You may also recall that, back in November 2012, the Spurs were fined $250,000 by the league after coach Popovich sent Duncan, Parker, Ginobili, and Green home right before a game against the Miami Heat.
So we want to rest our players to keep them healthy, but this cannot come at the expense of losing games. There are many factors to be taken into account here, such as players’ current physical condition, strength and tightness of schedule, and match-ups (how well a team stacks up against another team), to name a few. This is definitely not an easy problem. However, some insight is better than no insight at all. Therefore, let’s see what we can do with a simple O.R. model, and then we can talk about the strengths and weaknesses of our initial approach. (Here’s where you, dear reader, are supposed to chime in!)
Let’s begin with two simple assumptions: (i) when it comes to resting, we have to take players’ individual needs into account, i.e., we’ll use player-specific data; and (ii) when it comes to the likelihood of beating an opposing team, it’s better to think in terms of full lineups, rather than in terms of individual players, i.e., we’ll use lineup-specific data. The data in assumption (i) comes from doctors, players’ medical records, and coaches’ strategies. In essence, it boils down to one number: how many minutes, at most, should each player play in each game, under ideal circumstances. A useful measure of the strength of a lineup is its adjusted plus-minus score (see, for example, the work of Wayne Winston and his book Mathletics). In summary, it’s a number that tells you how many points a given lineup plays above (or below) an average lineup in the league over 48 minutes (or over 100 possessions, or another metric of reference).
For the sake of explanation, I’ll pretend to be in charge of resting Miami Heat players (surprise!). I’ll refer to a generic lineup by the letter 



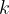
We’re now ready to begin. Fasten your seat belts!
What are the decisions to be made? Let’s consider a planning horizon that consists of the next 7 games (or pick your favorite number). So 

What are the constraints in this problem? There are three main constraints to worry about: (a) make sure to pick enough lineups to play each game in its entirety; (b) make sure your lineups are good enough to hopefully beat your opponents in each game; (c) keep track of players’ minutes, and don’t let them get out of hand. The next step is to represent each constraint mathematically.
Constraint (a): Pick enough lineups to completely cover each game. For every game

This means that if we sum the percentage of time each lineup is used during game
Constraint (b): Choose your lineups so that you expect to score enough points in every game to beat your opponents. In this example, I’ll focus on plus-minus scores, but as a coach you could focus on any metric that matters to you. Given a lineup 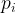


I want to emphasize two things. First,
Constraint (c): Keep track of how many minutes your players are playing above and beyond what you’d like them to play. For any given player 



The expression “
What is our goal? (a.k.a. objective function) It’s simple: we don’t want players to play too many minutes above

This minimizes the total overage in playing minutes. For a more balanced solution, it’s also possible to minimize the maximum overage over all players, or add weights in front of the
Now what? Well, the next step would be to solve this model and see what happens. I created a Microsoft Excel spreadsheet that can be solved with Excel Solver or OpenSolver. You can download it from here. Feel free to adapt it to your own needs and play around with it (this is the fun part!). Because my model was limited in size (I can’t use OpenSolver on my Mac at home), the solution isn’t very good (too many overage minutes). However, by adding more players and more lineups, the quality will certainly improve (use OpenSolver to break free from limits on model size). Here are some notes to help you understand the spreadsheet:
- Variables
- Variables
- Constraints (a) are implemented in rows 27, 28, 29.
- Constraints (b) are implemented in rows 33, 34, 35.
- The left-hand side of constraints (c) are in the range B74:J80. This range is required to be equal to the range B47:J53 (where the
- The objective function whose formula appears above is in cell J21.
What are the pros and cons of this model? Can you make it better? No model is perfect. There are always real-life details that get omitted. The art of modeling is creating a model that is detailed enough to provide useful answers, but not too detailed to the point of requiring an unreasonable amount of time to solve. The definitions of “detailed enough” and “unreasonable amount of time” are mostly client-specific. (What would please Erik Spoelstra and his coaching staff?) What do you think are the main strengths and weaknesses in the model I describe above? What would you change? Good data is a big issue in this particular case. If you don’t like my data, can you propose alternative sources that are practical? I believe there’s plenty to talk about in this context, and I’m looking forward to receiving your feedback. Maybe we can converge to a model that is good enough for me to go knocking on the Miami Heat’s door! (Don’t worry. In the unlikely event they open the door, I’ll share the consulting fees.)



I’ll start the conversation by pointing out two things: (1) This model is made to be solved and re-solved many times during the season as data gets updated; (2) Because it does not have integer-valued variables (i.e. it’s a linear programming model), we have access to sensitivity analysis. That means we can gain some understanding about the robustness of good solutions with respect to small changes in the data (but this will have to be the topic of another blog post).
I think this type of model would be useful for a coach to look at pre-game. I read this post yesterday, and then the Philadelphia Sixers beat the Miami Heat in their opening game. Now, Las Vegas has predicted that the Sixers will win only 16.5 games this year. Miami sat Dwayne Wade for the game, who needed to ice down both of his knees since he also played Tuesday. Who saw that coming? No one. I think an extension of this model (maybe looking a month or two out) for determining optimal games to sit these old/hurt players would also be helpful for decision support. This is proably an “easy” MIP extension. (quotes because I think it would be easy to model, but I’m unsure if it would be easy to solve).
Hi Andreas. Thank you for your comment. I agree with you completely. I had thought of the exact same thing you propose. Basically this MIP model would be the current model plus binary variables to pick the zeroes and ones that are currently fixed constants in the B38:J44 range of my Excel sheet (that is they’d pick the m_{jk} values).